🎶 정렬의 각 매커니즘에 대해 알아보자!
1. 삽입 정렬(INSERTION SORT)
삽입 정렬은 가장 간단한 정렬방식으로써, 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방법을 말한다.
정렬 방법은 다음과 같이 1회전에서는 1~2번째 원소를, 2회전에서는 1~3번째 원소를 비교해 순서대로 나열한다.

출력결과에서 확인할 수 있듯이, 비교 대상이 되는 key는 1회전부터 차례대로 2번째, 3번째의 원소의 값이 된다.

⚔️ 수행 시간 복잡도는 평균과 최악 모두 O(n^2) 이다.
2. 쉘 정렬(SHELL SORT)
쉘 정렬은 삽입정렬을 확장한 개념으로써, 입력파일을 '매개변수 h'의 값으로 서브파일을 구성하고, 각 서브파일을 삽입 정렬 방식으로 순서 배열하는 과정을 반복하는 정렬 방식이다. 일반적으로 h의 값은 입력 파일의 길이인 n의 3제곱근을 취한다.

출력 결과에서 확인할 수 있듯이, 초기 gap(=h)을 2로 설정했을 때에는 초기 key에서 2씩 떨어져 있는 원소끼리만 비교해서 정렬하고, 이 gap을 줄여나가며 gap이 1이 될때까지 반복해서 정렬하는 것이다.
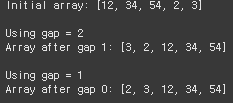
(🎃gap=2일 때, 12-54-3 -> 3-12-54로 정렬, 34-2 -> 2-34 로 정렬 / gap=1일 때, 삽입 정렬과 동일)
⚔️ 수행 시간 복잡도는 평균의 경우 O(n^1.5), 최악의 경우 O(n^2) 이다.
3. 선택 정렬(SELECTION SORT)
선택 정렬은 n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 n-1개 중에서 다시 최소값을 찾아 두 번째 레코드에 놓는 방식을 반복하는 정렬 방식이다.
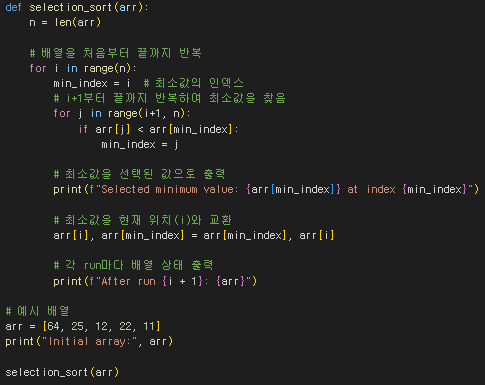
출력 결과에서 확인할 수 있듯이, 각 run마다 주어진 배열들 중 최소값을 찾아낸다.

⚔️ 수행 시간 복잡도는 평균과 최악 모두 O(n^2) 이다.
4. 버블 정렬(BUBBLE SORT)
버블 정렬은 주어진 파일에서 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방법으로써, '플래그 비트'를 활용해 정렬을 계속해서 수행할 것인지 체크한다.

실행 결과에서 확인할 수 있듯이, 1회전에서는 전체 배열을 대상으로 가장 큰 원소가 맨 뒤로 이동하게 되고, 2회전에서는 전체 배열 중 마지막 원소를 제외한 원소들 가운데 가장 큰 원소가 뒤로 이동하게 된다.
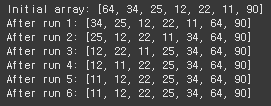
⚔️ 수행 시간 복잡도는 평균과 최악 모두 O(n^2) 이다.
다음 포스트에서는 퀵 정렬, 힙 정렬, 2-way 합병 정렬, 기수 정렬에 대해 알아보도록 하겠다.
'정보처리기사' 카테고리의 다른 글
| SW 신기술 - 증발품, OGSA, SOA, SaaS, CEP, 디지털 트윈, 텐서플로, 도커, 그리고 스크래피 (2) | 2025.01.23 |
|---|---|
| SW 신기술 - 인공지능, 뉴럴링크, 딥 러닝, 전문가 시스템, 가상현실, 증강현실, 혼합현실, 그레이웨어, 매시업, RIA, 그리고 시맨틱 웹 (1) | 2025.01.22 |
| OSI 참조 모델 - 물리, 데이터 링크, 네트워크, 전송, 세션, 표현, 응용 계층 (0) | 2025.01.18 |
| 운영체제(OS) - Windows(GUI, PnP, OLE), UNIX, LINUX 그리고 MacOS (2) | 2025.01.17 |
| 정규화(Normalization) - 1NF, 2NF, 3NF, BCNF, 4NF 그리고 5NF (1) | 2025.01.08 |
| 데이터베이스 설계 - 개념적, 논리적, 물리적 설계 (1) | 2025.01.06 |
| 자료 구조 - 선형 리스트, 스택, 큐, 데크, 그리고 그래프 (0) | 2025.01.04 |
| 정렬(SORT) - 퀵 정렬, 힙 정렬, 합병 정렬, 기수 정렬 (0) | 2025.01.03 |



