🎶 각 정렬 매커니즘에 대해 알아보자!
지난 포스트에서는 삽입 정렬, 쉘 정렬, 선택 정렬, 버블 정렬에 대해서 알아봤다.
정렬(sort) 1 - 삽입정렬, 쉘정렬, 선택정렬, 버블정렬
정렬(sort) 1 - 삽입정렬, 쉘정렬, 선택정렬, 버블정렬
🎶 정렬의 각 매커니즘에 대해 알아보자! 1. 삽입 정렬(INSERTION SORT)삽입 정렬은 가장 간단한 정렬방식으로써, 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬하는 방
ybbbb.tistory.com
이번 포스트에서는 퀵 정렬, 흽 정렬, 합병 정렬, 그리고 기수 정렬에 대해 알아보도록 하겠다.
1. 퀵 정렬(QUICK SORT)
퀵 정렬은 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방법으로써, 키를 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽 서브파일로 분해시키는 방식으로 정렬한다.

출력 결과에서 확인할 수 있듯이, 하나의 'pivot(=키)'를 설정하면 그 키를 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽으로 분할 및 재귀 호출하고 있다는 사실을 알 수 있다.
(🎃여기서 pivot을 고르는 방법은 다양할 수 있지만, 일반적으로는 첫 번째 원소를 pivot으로 설정한다.)
⚔️ 수행 시간 복잡도는 평균 O(nlogn), 최악의 경우 O(n^2)이다.
2. 힙 정렬(HEAP SORT)
힙 정렬은 '완전 이진 트리(Complete Binary Tree)'를 이용한 정렬 방법으로써, 주어진 파일 내 데이터들을 완전 이진 트리로 구성한 후, 가장 큰 값을 루트 노드로 전이시켜 하나씩 뽑아내는 과정을 거친다. 힙 정렬을 위해서는 이진 트리를 만들어주는 함수와, 힙 소트를 실제로 진행하는 함수, 총 2개의 함수가 필요하다.
(🎃완전 이진 트리란 마지막 레벨을 제외하고 모든 레벨이 완전히 채워져 있고, 마지막 레벨의 노드들은 가능한 한 왼쪽에 채워져 있는 트리를 말한다.)
출력 결과에서 확인해 볼 수 있듯이, 초기 데이터를 통해 이진 트리를 구성한 후, 루트 노드에서의 값을 pop한 후, 다시금 이진트리를 구성하는 방법을 반복하고 있다.
(🎃 트리 구조에 관해서는 나중에 따로 다루도록 하겠다. 여기서는, 최상단(=level 0)에 있는 데이터가 루트 노드라고 이해하면 충분하다.)
⚔️ 수행 시간 복잡도는 평균과 최악 모두 O(nlogn)이다.
3. 2-way 합병 정렬(MERGE SORT)
2-way 합병 정렬은 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 정렬 방식이다.
그 과정은 다음과 같은데,
- 두 개의 키들을 한 쌍으로 해 각 쌍에 대하여 순서를 정한다.
- 순서대로 정렬된 각 쌍의 키들을 합병하여 하나의 정렬된 서브리스트로 만든다.
- 위 과정에서 정렬된 서브리스트들을 하나의 정렬된 파일이 될 때까지 반복한다.
출력 결과에서 확인할 수 있듯이, 두 개씩 묶은 후 각각의 묶음 안에서 정렬하고, 묶여진 묶음을 또 두 개씩 묶어 정렬하는 방식을 반복한다.
⚔️ 수행 시간 복잡도는 평균과 최악 모두 O(nlogn)이다.
4. 기수 정렬(RADIX SORT) i.e. BUCKET SORT
기수 정렬은 'Queue'를 이용해 자릿수(Digit) 별로 정렬하는 방법으로, 레코드의 키 값을 분석해 같은 수 또는 같은 문자끼리 그 순서에 맞는 버킷에 분배 했다가 버킷의 순서대로 레코드를 꺼내 정렬한다.
(🎃 큐(queue)는 자료 구조 중 하나로써, 먼저 들어온 데이터가 먼저 나가는 정책(FIFO)을 따른다)

출력 결과에서 확인할 수 있듯이, 1의 자리부터 각 자리에 맞는 큐(queue)에 저장한 후, 큐에서 값을 꺼내 다시 배열에 저장하는 방식을 반복한다.
(🎃큐에서 값을 꺼내 다시 배열에 저장하지 않고 다음 자릿수로 넘어간다면, 이전 자릿수에서 정렬한 결과를 활용하지 못하게 되므로 정렬이 이루어지지 않는다! 즉, 10의 자릿수에서 같은 값이지만 1의 자릿수에서 더 큰 값이 앞에 오는 경우가 생길 수 있다.)
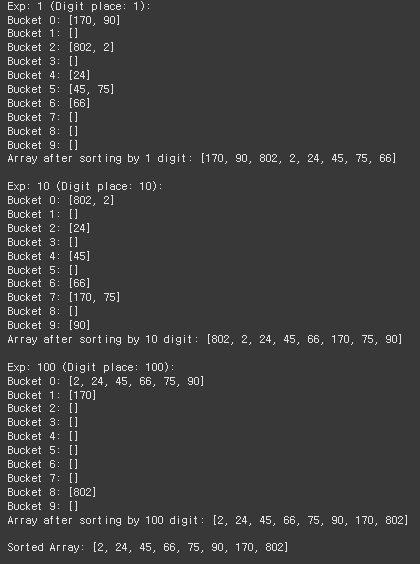
⚔️ 수행 시간 복잡도는 평균과 최악 모두 O(dn)이다.
(🎃여기서 d는 기수, n은 데이터의 길이를 의미한다.)
지금까지 정보처리기사에서 다루는 정렬 매커니즘에 대해서 알아봤다. 꼭 한 번씩 직접 구현해보길 바란다.
'정보처리기사' 카테고리의 다른 글
| SW 신기술 - 증발품, OGSA, SOA, SaaS, CEP, 디지털 트윈, 텐서플로, 도커, 그리고 스크래피 (2) | 2025.01.23 |
|---|---|
| SW 신기술 - 인공지능, 뉴럴링크, 딥 러닝, 전문가 시스템, 가상현실, 증강현실, 혼합현실, 그레이웨어, 매시업, RIA, 그리고 시맨틱 웹 (0) | 2025.01.22 |
| OSI 참조 모델 - 물리, 데이터 링크, 네트워크, 전송, 세션, 표현, 응용 계층 (0) | 2025.01.18 |
| 운영체제(OS) - Windows(GUI, PnP, OLE), UNIX, LINUX 그리고 MacOS (2) | 2025.01.17 |
| 정규화(Normalization) - 1NF, 2NF, 3NF, BCNF, 4NF 그리고 5NF (0) | 2025.01.08 |
| 데이터베이스 설계 - 개념적, 논리적, 물리적 설계 (0) | 2025.01.06 |
| 자료 구조 - 선형 리스트, 스택, 큐, 데크, 그리고 그래프 (0) | 2025.01.04 |
| 정렬(SORT) - 삽입 정렬, 쉘 정렬, 선택 정렬, 버블 정렬 (0) | 2025.01.02 |



