🎶 앙상블 이하 Ensemble Method에 대해 알아보자.
앙상블이란,
머신러닝의 민주주의라고도 부르며, 여러 분류기가 각자의 분류 결과를 투표하듯이 내어 놓으면 가장 많은 표를 얻은 결과를 최종 결과로 선택하는 방법이다.
(🎃 Majority Voting 라고도 부른다.)
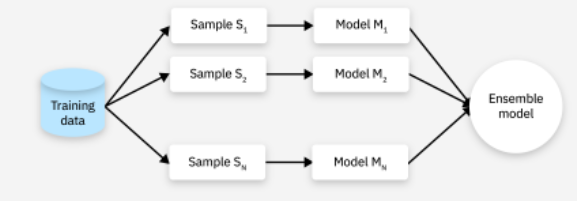
어느 수준의 성능에 도달하면 분류기를 개선하는 일이 매우 어려워지기 때문에, 여러 가지 종류의 분류기를 개별적으로 개선하는 데에 한계가 있을 때 이들의 협력을 이용하는 것이 바로 앙상블인 것이다.
앙상블의 각 모델들은 성격이 서로 다른 것, 즉 개별 분류기의 다양성이 좋아야 앙상블의 성능도 좋아진다. 이 분류기의 다양성을 확보하는 방법이
- 서로 다른 모델로 각각의 분류기를 만들고,
- 각각의 분류기에 대해 서로 다른 학습 데이터를 제공해 훈련하는 것이다.
앙상블의 종류로는 다음과 같은 것들이 있다.
1. 배깅(Bagging) - 동종 병렬 방법
배깅은 주어진 데이터를 Bootstrap 하는데, Bootstrap sampling 하는 과정에서 replacement 를 활용한다. 즉, 복원 랜덤 샘플링 과정을 통해 bootstrap 한 데이터들로 각 모델을 학습시킨 후, 학습된 모델의 결과를 집계하여 최종 결과 값을 리턴한다.

배깅의 가장 대표적인 예로는 랜덤 포레스트로, 무작위 Decision Trees의 앙상블로 구성돼 있다.
2. 부스팅(Boosting) - 순차적 앙상블 방법
부스팅은 배깅과 매우 유사한 방식으로 작동하지만, 가중치를 활용한다는 가장 큰 차이점이 존재하는 앙상블 방법이다. 모델이 예측을 진행하면 그 예측 결과에 따라 데이터에 가중치가 부여되고, 부여된 가중치가 다음 모델에 영향을 주게 된다. 즉, 잘못 분류된 데이터에 집중하여 새로운 분류 규칙을 만드는 단계를 반복하는 것이다.

부스팅의 대표적인 예로는 AdaBoost와 Gradient Boost 가 있다.
3. 스태킹
스태킹(또는 스택 일반화)은 각 학습 데이터에 대해 다른 알고리즘을 사용해 동일한 데이터 셋에 대해 각각 다른 모델들을 구체적으로 훈련시킨 후, 다른 모델들로부터 나오는 예측 값들을 메타 모델인 최종 모델의 훈련 데이터셋으로 활용하는 방법이다.

더 자세한 설명을 원하면 다음 IBM 자료를 참고하길 바란다.
앙상블 학습이란 무엇인가요? | IBM
앙상블 학습이란 무엇인가요? 이 ML 방법이 모델을 집계하여 예측을 개선하는 방법 알아보기
www.ibm.com
'머신러닝' 카테고리의 다른 글
| [RL] 강화학습 - 근사 Q-러닝과 심층 Q-러닝 개념 및 Python 구현 (0) | 2025.04.18 |
|---|---|
| [RL] 강화학습 - Q-러닝 개념, 수식 및 Python 구현, 그리고 입실론-그리디 정책 (1) | 2025.04.14 |
| [RL] 강화학습 - 마르코프 결정 과정과 벨만 최적 방정식, Q-가치 반복 알고리즘, 그리고 Python 구현 (0) | 2025.04.10 |
| OpenAI Gym - OpenAI Gym 개념과 cartPole-v1, 그리고 정책 하드코딩 (0) | 2025.04.06 |
| [RL] 강화학습(Reinforcement Learning) - 에이전트, 정책, 정책탐색, 환경, 리턴, 할인율 (2) | 2025.01.16 |
| [RL] 강화학습 알고리즘 - PPO (Proximal Policy Optimization) with TRPO, Clipped Surrogate Objective, GAE, 상태가치함수, 엔트로피 보너스 (2) | 2025.01.15 |
| SVM(Support Vector Machine) - 소프트 마진과 하드 마진, 그리고 커널 트릭 + python 구현까지! (0) | 2025.01.07 |
| K-means clustering 에 대해 알아보고 python 으로 구현해보자! (0) | 2025.01.05 |



