🎶 Q-러닝의 문제점을 해결하기 위해 등장한 근사 Q-러닝과 심층 Q-러닝에 대해 알아보고 python으로 구현해보자.
1. 근사 Q-러닝과 심층 Q-러닝
Q-러닝의 주요 문제점은 바로 많은 상태와 행동을 가진 대규모의 MDP에는 적용하기 어렵다는 것이다. 가능한 상태가 기하급수적으로 늘어날 경우, 모든 Q-가치에 대한 추정값을 기록할 수 있는 방법이 없기 때문이다.
해결책으로 먼저 등장한 방법으로는 어떤 상태-행동 (s, a) 쌍의 Q-가치를 근사하는 함수 Q(θ)(s, a)를 적절한 개수의 파라미터를 사용해 찾는 근사 Q-러닝이 있다. 하지만 곧이어 이 근사 Q-러닝보다 더 나은 결과를 내는 러닝 방법이 등장했는데, 그것이 바로 심층 Q-러닝이다.
심층 Q-러닝은 Q-가치를 추정하기 위해 DNN, 내지는 심층 Q-네트워크(DQN)를 사용하는 방법으로써, 특히 복잡한 문제에서 훨씬 더 나은 성능을 보여줬다. 이제 이 심층 Q-러닝을 python으로 직접 구현해보자.
2. Python 구현
심층 Q-러닝을 구현하기 위해 가장 먼저 필요한 것은 바로 심층 Q-네트워크다. 이론적으로는 상태-행동 쌍을 입력받고 근사 Q-가치를 출력하는 신경망이 필요하지만, 실전에서는 상태만 입력으로 받고 가능한 모든 행동에 대한 근사 Q-가치를 각각 출력하는 것이 더욱 효율적이다.
import tensorflow as tf
input_shape = [4] # observation_space
n_outputs = 2 # action_space
# 신경망 모델 정의
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation="elu", input_shape=input_shape),
tf.keras.layers.Dense(32, activation="elu"),
tf.keras.layers.Dense(n_outputs)
])
에이전트가 환경을 탐험하도록 만들기 위해 앞서 살펴본 입실론-그리디 정책을 사용한다.
import numpy as np
def epsilon_greedy_policy(state, ep=0):
if np.random.rand() < ep:
return np.random.randint(n_outputs)
else:
Q_values = model.predict(state[np.newaxis], verbose=0)[0]
return Q_values.argmax()
최근의 경험에만 의지해 DQN을 훈련하는 대신, 재생 버퍼(재생 메모리)에 모든 경험을 저장하고 훈련 반복마다 여기에서 랜덤한 훈련 배치를 샘플링하는 방법을 사용해 경험과 훈련 배치 사이의 상관관계를 줄어들도록 해보자.
from collections import deque
replay_buff = deque(maxlen=2000)
경험은 총 원소 6개로 구성되는데, 차례로 상태, 선택한 행동, 결과 보상, 다음 상태, 에피소드 종료 여부, 에피소드 중단 여부 이다.
def sample_exp(batch_size):
indices = np.random.randint(len(replay_buff), size=batch_size)
batch = [replay_buff[index] for index in indices]
return[
np.array([experience[field_index] for experience in batch])
for field_index in range(6)
]
# states, actions, rewards, next_states, dones, truncateds
입실론 그리디 정책을 활용해 하나의 스텝을 플레이하고 반환된 경험을 재생 버퍼에 저장하는 함수를 정의하자.
def play_step(env, state, ep):
action = epsilon_greedy_policy(state, ep)
next_state, reward, done, truncated, info = env.step(action)
replay_buff.append((state, action, reward, next_state, done, truncated))
return next_state, reward, done, truncated, info
이제 재생 버퍼에서 경험 배치를 샘플링하고 이 배치에서 경사 하강법 한 스텝을 수행하여 DQN을 훈련시키는 함수를 정의하자.
batch_size = 32 # 배치 크기
discount = 0.95 # 할인율
optimizer = tf.keras.optimizers.Nadam(learning_rate=1e-2) # 경사하강법 최적화 알고리즘
loss_fn = tf.keras.losses.MSE # 손실함수
def training_step(batch_size):
experiences = sample_exp(batch_size)
states, actions, rewards, next_states, dones, truncateds = experiences
next_Q_values = model.predict(next_states, verbose=0)
max_next_Q_values = next_Q_values.max(axis=1)
runs = 1.0 - (dones | truncateds)
target_Q_values = rewards + runs * discount * max_next_Q_values
target_Q_values = target_Q_values.reshape(-1, 1)
mask = tf.one_hot(actions, n_outputs)
with tf.GradientTape() as tape:
all_Q_values = model(states)
Q_values = tf.reduce_sum(all_Q_values * mask, axis = 1, keepdims= True)
loss = tf.reduce_mean(loss_fn(target_Q_values, Q_values)) # 모델의 손실값 계산
# 경사 하강법을 활용해 모델의 파라미터 학습
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
코드에서 사용되는 경사하강법의 최적화 알고리즘에 관련되서는 다음 블로그를 참고하길 바란다.
경사 하강법의 최적화 - 모멘텀(momentum), 네스테로프가속경사(Nesterov-accelerated gradient), AdaGrad, RMSProp 그리고 Adam
경사 하강법의 최적화 - 모멘텀(momentum), 네스테로프가속경사(Nesterov-accelerated gradient), AdaGrad, RMSPro
🎶 경사 하강법의 최적화 기법에는 어떤 것들이 있을까? 지난 포스트에서는 경사하강법에 의한 파라미터 업데이트가 잘 이루어지지 않는, 사라지는 기울기 문제에 대해 다뤘었다.사라지는 기
ybbbb.tistory.com
마지막으로 모델 훈련 코드를 짜보고 각 episode에 받는 최종 reward를 시각화해보자.
import gymnasium as gym
import matplotlib.pyplot as plt
env = gym.make("CartPole-v1")
rewards = []
for episode in range(200):
obs, info = env.reset()
total_reward = 0
for step in range(50):
ep = max(1-episode / 200, 0.01)
obs, reward, done, truncated, info = play_step(env, obs, ep)
total_reward += reward
if done or truncated:
break
rewards.append(total_reward)
if episode > 50:
training_step(batch_size)
# 보상 그래프 시각화
plt.plot(range(200), rewards)
plt.show()
각 에피소드별로 받은 보상값을 시각화한 결과는 다음과 같다.
이처럼 최대 보상 근처에서 안정된 것처럼 보였으나 다시 점수가 떨어지는 구간이 있는데, 이것이 바로 모든 RL 알고리즘이 직면한 문제인 '최악의 망각(catastrophic forgetting) 문제'이다.
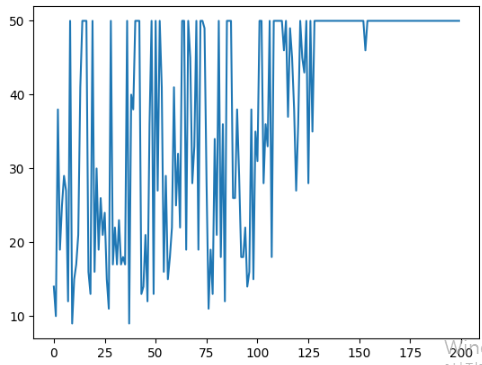
강화 학습은 대부분의 훈련이 불안정하고 하이퍼파라미터 값와 랜덤 시드의 선택에 크게 민감하기 때문에 매우 어렵다. 이에 우수한 강화학습을 위해서는 적절한 하이퍼파라미터 튜닝과 함께 운이 따라줘야 한다는 우스갯소리가 있다.
'머신러닝' 카테고리의 다른 글
| 오토인코더, GAN(생성적 적대 신경망), 확산 모델의 개념 (0) | 2025.04.24 |
|---|---|
| [RL] 강화학습 - 심층 Q-러닝 알고리즘의 여러 가지 변형 (0) | 2025.04.20 |
| [RL] 강화학습 - Q-러닝 개념, 수식 및 Python 구현, 그리고 입실론-그리디 정책 (2) | 2025.04.14 |
| [RL] 강화학습 - 마르코프 결정 과정과 벨만 최적 방정식, Q-가치 반복 알고리즘, 그리고 Python 구현 (0) | 2025.04.10 |
| OpenAI Gym - OpenAI Gym 개념과 cartPole-v1, 그리고 정책 하드코딩 (0) | 2025.04.06 |
| 앙상블(Ensemble) - 배깅(Bagging), 부스팅(Boosting), 스태킹 (0) | 2025.01.30 |
| [RL] 강화학습(Reinforcement Learning) - 에이전트, 정책, 정책탐색, 환경, 리턴, 할인율 (2) | 2025.01.16 |
| [RL] 강화학습 알고리즘 - PPO (Proximal Policy Optimization) with TRPO, Clipped Surrogate Objective, GAE, 상태가치함수, 엔트로피 보너스 (2) | 2025.01.15 |


