🎶 강화학습 알고리즘 중 하나인 Q-러닝 알고리즘에 대해 알아보자.
0. 들어가기 전에
독립적인 행동으로 이루어진 강화 학습 문제는 보통 전 포스트에서 기술했던 마르코프 결정 과정으로 모델링될 수 있지만, 초기에 에이전트는 전이 확률에 대해 알지 못하기 때문에 보상이 얼마나 되는지도 알지 못한다. 즉, T와 R을 알지 못하기 때문에, 적어도 한 번씩은 각 상태와 전이를 경험해봐야 한다.
[RL] 강화학습 - 마르코프 결정 과정과 벨만 최적 방정식, Q-가치 반복 알고리즘, 그리고 Python 구현
[RL] 강화학습 - 마르코프 결정 과정과 벨만 최적 방정식, Q-가치 반복 알고리즘, 그리고 Python 구현
🎶 강화학습을 위한 알고리즘 중 하나인 마르코프 결정 과정에 대해 알아보자. 1. 마르코프 결정 과정1950년대 리처드 벨만(Richard Bellman)이 논문으로 처음 기술한 이 과정은 마르코프 연쇄를 활
ybbbb.tistory.com
'시간차 학습(TD 학습)'은 Q-가치 반복 알고리즘과 매우 비슷하지만 에이전트가 MDP에 대해 일부 정보만 알고 있을 때를 다룰 수 있도록 변형한 것이다. 여기서 에이전트는 '탐험 정책(exploration policy)'을 사용해 MDP를 탐험하는데, 탐험이 진행될수록 TD 학습 알고리즘이 실제로 관측된 전이와 보상에 근거해 상태 가치의 추정값을 업데이트해 나간다.
바로 오늘 다룰 Q-러닝 알고리즘이 이 TD 학습 알고리즘의 한 종류이다.
1. Q-러닝 이란?
Q-러닝 알고리즘은 전이 확률과 보상을 초기에 알지 못하는 상황에서 Q-가치 반복 알고리즘을 적용한 것이다. Q-러닝은 에이전트가 플레이하는 것을 보고 점진적으로 Q-가치 추정을 향상하는 방식으로 작동하는데, 정확한 Q-가치 추정을 얻게 되면 최적의 정책은 가장 높은 Q-가치를 가지는 행동을 선택한다. 이를 '탐욕적 정책(greedy policy)' 라고 한다.

각 상태-행동 (s, a) 쌍마다 이 알고리즘이 행동 a를 선택해 상태 s를 떠났을 때 에이전트가 받을 수 있는 보상 r과 기대할 수 있는 할인된 미래 보상의 합을 더한 이동 평균을 저장한다. 미래 보상의 합을 추정하기 위해서는 타깃 정책이 이후로 최적으로 행동한다고 가정하고 다음 상태 s'에 대한 Q-가치 추정의 최댓값을 선택해야 한다.
2. Python으로 구현
Q-러닝 알고리즘을 Python을 활용해 직접 구현해보자.
먼저 에이전트가 환경을 탐색하게 만들어야 하기 때문에, 에이전트가 한 행동을 실행하고 결과 상태와 보상을 받을 수 있는 스텝 함수를 만든다.
import numpy as np
def step(state, action):
probas = transition_proba[state][action]
next_state = np.random.choice([0,1,2], p=probas)
reward = rewards[state][action][next_state]
return next_state, reward
이제 에이전트의 탐색 정책을 구현할텐데, 상태 공간이 매우 적기 때문에 단순한 랜덤 정책으로 이를 구현하도록 하겠다.
def explor_policy(state):
return np.random.choice(possible_actions[state])
이제 Q-러닝 알고리즘을 실행해보자.
alpha0 = 0.05 # 초기 학습률
decay = 0.005 # 학습률 감쇠
gamma = 0.90 # 할인 계수
state = 0 # 초기 상태
# 상태 S 에서 S' 으로 상태 전이할 확률
transition_proba = [
[[0.5, 0.0, 0.5], [0.0, 0.0, 1.0]],
[[0.7, 0.1, 0.2], [0.0, 0.95, 0.05]],
[[0.4, 0.0, 0.6], [0.3, 0.3, 0.4]]
]
# 상태 S 에서 S' 으로 상태 전이할 때 받는 보상
rewards = [
[[0,0,0], [0,0,0]],
[[+5,0,0], [0,0,0]],
[[0,0,0], [-1,0,0]]
]
# 각 상태에서 가능한 행동집합
possible_actions = [[0,1], [0,1], [0,1]]
# Q-가치 초기화
Q_values = np.full((3,2), -np.inf)
for state, actions in enumerate(possible_actions):
Q_values[state, actions] = 0.0 # 가능한 모든 행동에 대해서 0으로 초기화
# Q-러닝
for iteration in range(10000):
action = explor_policy(state)
next_state, reward = step(state, action)
next_value = Q_values[next_state].max() # 탐욕적 정책 수행
alpha = alpha0 / (1 + iteration * decay)
Q_values[state, action] *= 1 - alpha
Q_values[state, action] += alpha * (reward + gamma * next_value)
state = next_state
참고로, Q-러닝 알고리즘은 훈련된 정책을 훈련 중에 반드시 사용하는 것은 아니기 때문에 Q-러닝 알고리즘을 '오프-폴리시(off-policy) 알고리즘'이라고 한다. 예로 위의 코드에서 실행된 정책은 완전히 랜덤한 정책이며 훈련된 정책은 전혀 사용되지 않지만, 하이퍼파라미터를 적절히 튜닝하고 많은 반복횟수를 수반하면 최적의 정책을 학습하는 능력이 생기게 된다.
3. 탐험 정책
물론 Q-러닝은 탐험 정책이 MDP를 충분히 탐험해야 작동하기 때문에 극단적으로 시간이 너무 오래 걸릴 수 있다는 단점이 있다. 따라서, 'ε-그리디 정책(ε-greedy policy)' 를 사용한다. 즉, 각 스텝에서 ε 확률로 랜덤하게 행동하거나, 1-ε 확률로 그 순간의 가장 높은 Q-가치를 선택해 행동한다. 일반적으로 ε의 값은 1.0에서 시작해 0.05까지 점점 감소하는 것이 일반적이다.
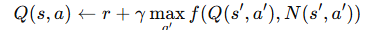
여기서 N(s', a')는 상태 s'에서 행동a'를 선택한 횟수를 카운트하고, f(Q, N)은 입실론-그리디 정책과 같은 탐험 함수를 의미한다.
'머신러닝' 카테고리의 다른 글
| 오토인코더 - 기본 개념 및 PCA 수행, 그리고 적층 오토인코더 python 구현 (0) | 2025.04.26 |
|---|---|
| 오토인코더, GAN(생성적 적대 신경망), 확산 모델의 개념 (0) | 2025.04.24 |
| [RL] 강화학습 - 심층 Q-러닝 알고리즘의 여러 가지 변형 (0) | 2025.04.20 |
| [RL] 강화학습 - 근사 Q-러닝과 심층 Q-러닝 개념 및 Python 구현 (0) | 2025.04.18 |
| [RL] 강화학습 - 마르코프 결정 과정과 벨만 최적 방정식, Q-가치 반복 알고리즘, 그리고 Python 구현 (0) | 2025.04.10 |
| OpenAI Gym - OpenAI Gym 개념과 cartPole-v1, 그리고 정책 하드코딩 (0) | 2025.04.06 |
| 앙상블(Ensemble) - 배깅(Bagging), 부스팅(Boosting), 스태킹 (0) | 2025.01.30 |
| [RL] 강화학습(Reinforcement Learning) - 에이전트, 정책, 정책탐색, 환경, 리턴, 할인율 (2) | 2025.01.16 |


